Unsupervised Learning Assignment Help (Simplify Unsupervised Learning Assignments with our Professio
Order Now
Why Choose The Programming Assignment Help?
On Time Delivery
Plagiarism Free Service
24/7 Support
Affordable Pricing
PhD Holder Experts
100% Confidentiality

I am happy with the quality of the writing and the lack of plagiarism detected.
The writer provided a unique perspective without any plagiarism detected.
I appreciate the effort put into creating original content for my assignment.
Unsupervised Learning Assignment Help | Unsupervised Learning Homework Help
Machine learning has become the talk of the technology world. Students are showing interest to pursue this course with its introduction to the curriculum of many colleges and universities globally. However, the most challenging part for every student while pursuing this course is to work on the assignments related to this topic. Due to a lack of time or lack of knowledge, they seek the help of experts. Therefore, we have a team of Unsupervised Learning Assignment Help experts who use their real-time experience and knowledge to work on your tasks and help you score flying grades in the final examination.
Our experts always aim to provide excellent assignment help at Unsupervised Learning Assignment Help and Unsupervised Learning Homework Help Our experienced team of writers and researchers will write a perfect assignment document according to your expectations. After completion of your assignment, they will also deliver it on time without making any errors.
We have a skilled team of Programmers who are well-versed in Python, machine learning, artificial intelligence, Deep Learning, supervised learning, unsupervised learning & the latest developments in the technological arena. These machine-learning assignment helpers can write excellent codes for you.
Why Do Students Seek Unsupervised Learning Assignment Help?
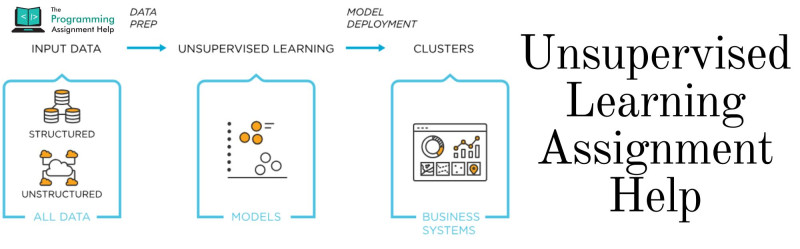
Unsupervised machine learning will make use of different algorithms to thoroughly analyse the datasets which are unlabelled. The algorithms used will be finding the patterns hidden in the data and grouping them together without any human inference and understanding the data by itself. It can find out the differences as well as similarities in the data to come up with the solution for data analysis, customer segmentation and image recognition. Many students find it challenging to complete the task and end up submitting a poor-quality assignment as a result of which they lose valuable grades. We have a team who can complete the assignments, be the topic is simple or complicated in the given time and help you get appreciation and secure good grades.
Unsupervised Learning Approaches Use in Solving Programming Assignments & Homework
There are different models used in unsupervised learning such as clustering, association and dimensionality reduction.
- Clustering: It is the most widely used data mining technique that will group the unlabelled data based on the differences as well as similarities between the datasets. The clustering process will be used to process the raw data objects which are unclassified into groups and these are presented in the form of structures and patterns in the data. Clustering algorithms will be categorized into different types which include overlapping, hierarchical and probabilistic.
- Overlapping and exclusive clustering: Exclusive clustering is a type of grouping that would ensure that the data point would exist only in a single cluster. It is referred to as hard clustering. The K-means clustering is the best example of this. It is the clustering method that assigns data points into different K groups here K would indicate the total clusters depending on the distance from the centroid. The data point that is closer to the centroid would be put together in the same category. The K value will have smaller groups with higher granularity whereas the smaller K value will have bigger groups with less granularity. This type of clustering is widely used in image segmentation and document clustering.
- Hierarchical clustering: It is also known as hierarchical cluster analysis in the unsupervised learning algorithm, which can either be agglomerative or divisive. The agglomerative clustering is known as the bottoms-up approach. In this type of clustering, the data points would be put into groups and later merged together in an iterative manner based on the similarity until a cluster is attained. Different methods used to measure similarity are – ward’s linkage, average linkage, complete linkage, and single linkage.
- Probabilistic clustering: It is a type of unsupervised technique that will help you solve density estimation or clustering issues. In this type of clustering, the data points would be clustered based on their similarities. The Gaussian Mixture Model is the widely used probabilistic method.
- Dimensionality reduction: If you have huge chunks of information, using this you can reap precise results and this also has a huge impact on machine learning algorithms. However, with huge data, it becomes difficult to visualize the datasets. Dimensionality reduction is a kind of technique when features and dimensions in datasets are too many. This cuts down the data inputs to the size you want and preserves the dataset's integrity.
Some of the popular topics in Unsupervised Learning on which our programming assignment help experts work on a daily basis are listed below:
| k-Means Algorithms | Singular Value Decomposition |
| Decision Tree | Manifold Learning |
| Naive Bayes | Isomap |
| Support Vector Machine | t-distributed stochastic neighbor embedding |
| Semisupervised and Other Learners | Dictionary Learning |
| Overfitting | Independent Component Analysis |
| Data Drift | Latent Dirichlet Allocation |
| Linear Projection |
Hierarchiocal Clustering
|
| Principal Component Analysis | Autoencoders |
Assignments Based On Applications of Unsupervised Learning
Machine learning techniques are widely used to boost the experience of users while using any product and are also used to rigorously test the system to assure quality. This type of learning will provide you with the exploratory path to see the data and find out the patterns in huge data more briskly than manual observations.
- News articles - Many top news media sites will use an unsupervised learning algorithm to categorize the articles based on the stories. This helps you to manually avoid categorizing the articles.
- Computer vision - Unsupervised learning algorithms will be used to carry out different visual perception activities which include object recognition.
- Medical imaging - Unsupervised machine learning is also used in medical imaging devices such as image detection, classification, and segmentation for radiology and pathology to find out the patient's health problem and diagnose them immediately.
- Anomaly detection - Unsupervised learning models will go through large data and find out the data points in a dataset. The anomalies would bring awareness about faulty equipment, breaches in security and human errors.
Students come to our programming assignment helpers and ask multiple queries on the unsupervised learning topic. Some of these queries are listed below:
- Do you train unsupervised learning?
- Are data model bias and variance challenges with unsupervised learning?
- Does unsupervised learning need training data?
- Is unsupervised learning machine learning?
- What's the term for children who are unsupervised by an adult after school?
- Is prediction supervised or unsupervised?
- Is classification an unsupervised learning method?
- Does unsupervised learning classify data?
- Is logistic regression supervised or unsupervised?
- Is reinforcement learning unsupervised?
- Is expectation maximization unsupervised learning?
- Is K means clustering supervised or unsupervised?
- Does unsupervised learning need labelled data?
- Is spectral clustering supervised or unsupervised?
- Is gradient boosting supervised or unsupervised?
If you are facing similar queries while solving Unsupervised Learning Assignments & homework then seek the help of our programming assignment help experts.
Why Do Students Choose Us To Work On Unsupervised Learning Assignments?
We offer the best online Unsupervised Learning Assignment Help to students on their assignments related to machine learning. A few of the perks that a student can get by availing of our services include:
- On-time delivery - Our machine learning experts will deliver the task on time as we understand how important it is for students to meet deadlines and avoid losing good grades. We submit the assignments before the given timeline so that you can have enough time to go through the task prior to submitting it to your professors.
- Experienced machine learning experts - We have a team of machine learning experts who hold ample experience and knowledge to work on your assignments and deliver flawless output.
- Free revisions - We do not charge anything to revise the content. In case we missed adding any requirement that is given by you or wants us to tweak the assignment, we do it for free.
- Affordable pricing - Our pricing structure is affordable for all students with tight budgets. Every student can afford to avail of our service without burning holes in their pockets. Though our service is cost-effective yet our quality is maintained top-notch.
If you have to complete the machine learning assignment and have no time, seek our help.